

「ゼロから作る Deep Learning」で機械学習を学ぶ その09 CIFAR-10でテスト正答率81.4%を達成
2025-08-19 15:56:44
- Tags:
- Python
- Deep Learning
前回の続き。
ソースは下記
ryotakato/de_zero
CIFAR-10のテスト正答率をあげるために、
全体の構造を見直してみる。
下記は前回のモデルを、MNISTを通したときの流れを図示したもの。
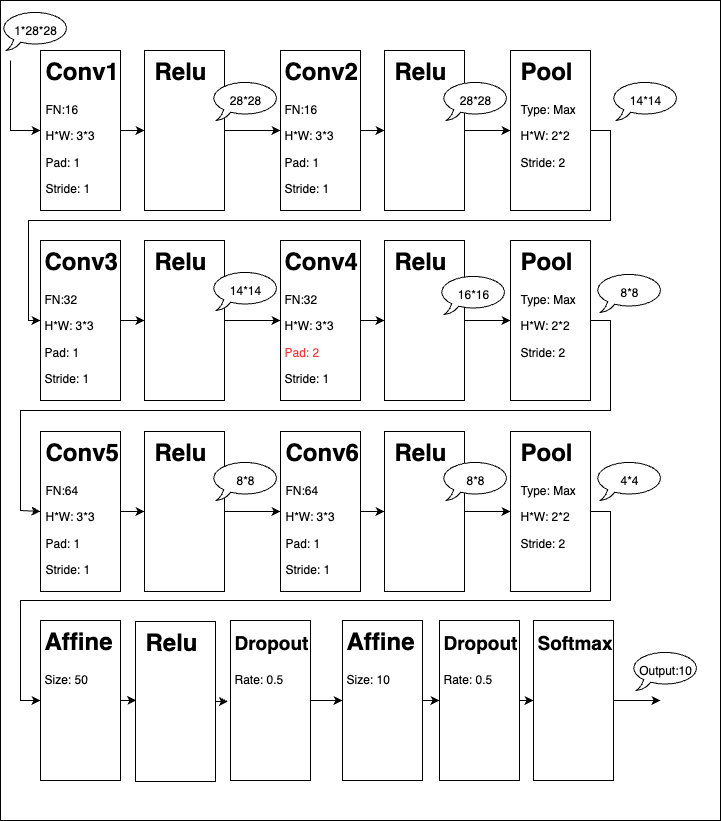
Conv1(畳み込み層)は、FN(フィルター数)が16個、H*W(フィルターサイズ)が 3*3、Pad(パディング数)が1、Stride(ストライド数)が1という感じで表現している。
各畳み込み層は、Reluをかけ、2回畳み込んだところでPoolのMaxプーリング層(H*Wが2*2で、Strideも2)により要素数を圧縮している。
最後にAffine層から始まる全結合層をかけているが、
1個目のAffine層は、隠れ層が50にしてあり、
2個目のAffine層は、もう出力なので、MNISTの出力10にしてある。
各吹き出しは、MNISTの一つの画像をこのCNNに投入したときの画像の高さと幅の変化を示している。
MNISTは28*28のグレースケール画像なので、チャンネル数は1。よって、最初の投入時は、1*28*28 となっている。
今回はチャンネルは1つだけだからあまり関係ないけど、通常畳み込み層1つ目を通過した時点で画像のチャンネルは1つにまとめられるので、
それ以降の吹き出しではチャンネル数は書いていない。
畳み込み層を通過すると、画像のサイズは、
高さ = ((元の高さ + (2 * パディング数) - フィルター高さ) / ストライド数 ) + 1
で計算される(幅も同じ)
そのため、今回の設定では、畳み込み後も画像サイズは変わっていない。
上の図では、Reluのところに吹き出し描いてあって紛らわしいけど、まあ、Relu通過しても画像サイズは変わらないので、言いたいことは伝わると思う。
で、画像サイズが変わるのは、プーリング層を通過したとき。
ここでは、
高さ = ((元の高さ - フィルター高さ) / ストライド数) + 1
となるので、
今回の設定では画像サイズが高さ、幅ともに半分になる。
特別なのは、赤く塗ったConv4のパディング数。
他と同じく1のままだと、後続のプーリング層で、7*7の奇数になってしまうので、
ここではきっとあえてパディングを2にして、Conv4を通過したときに16*16に増えるようにしていると思われる。
結果としてプーリング層を通過したとき、8*8になる。
奇数じゃダメなの?って感じはするが、
きっと、Conv5やConv6は、今回の設定(ストライドが1)だと別に問題ないのだが、
その後のプーリング層で、7*7を半分にすると、小数点が切り捨てられて3*3になってしまう(本書のプーリング層のプログラムではそういう計算になる)ため、
Affineに入る前におそらく情報が落ちてしまうのではないかと思われる。
ここまで考察したところで、前回のCIFAR-10で73%を達成したプログラムを考えてみると、
上記の情報落ちが発生していたような気がする。
なぜなら、CIFAR-10は32*32なので、Conv4でパディングを2にしなくても偶数のサイズになるからだ(32 -> 16 -> 8)。
また、そもそもフィルター数などが、
CIFAR-10の1画像あたり3072画素(MNISTは1画像あたり784画素)を表現するには4倍ぐらい足りていないと思ったので、
後述する参考URLを元に、フィルター数などを4倍に増やしてみた。
結果今回81.4%を達成したCNNの構造が下記。
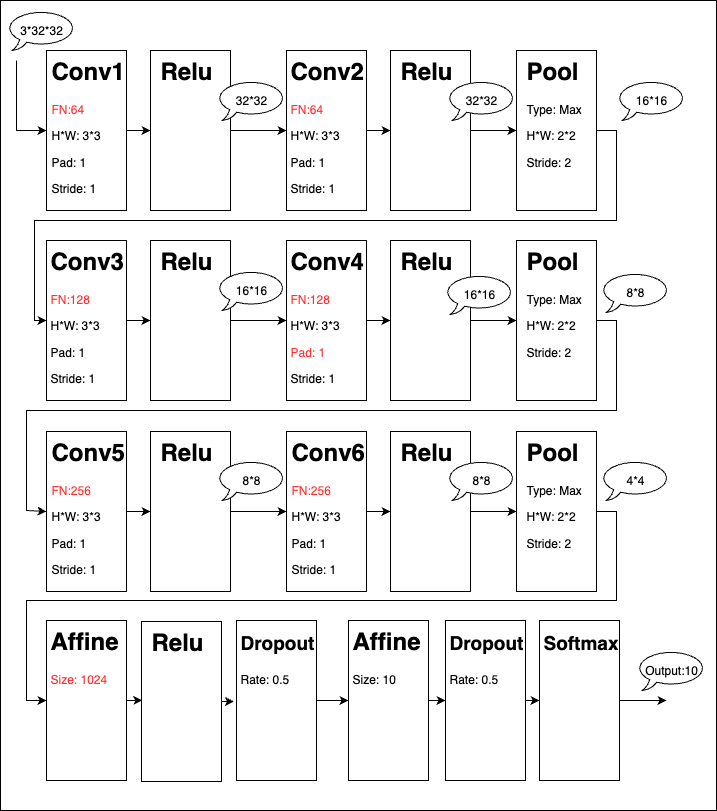
赤字が変更したところ。
吹き出しはCIFAR-10の画素数。
1個目のAffine層も思い切って1024に増やしている。
なお、epoch数も前は20だったんだけど、気持ち増やして、25まで増やしている。
そのため、iterationは12500回になった。
さて、実際にやってみた正答率の変化のグラフが・・・
はい、すみません、画像スクショできていませんでしたー。(なんでこの大事なところで・・・)
とりあえずやったデータとしては、
=== max epoch: 25, max iter: 12500, iter per epoch: 500.0, train size: 50000 ===
=== epoch:1, train_acc:0.518, test_acc:0.511 ===
=== epoch:2, train_acc:0.636, test_acc:0.635 ===
=== epoch:3, train_acc:0.731, test_acc:0.703 ===
=== epoch:4, train_acc:0.774, test_acc:0.74 ===
=== epoch:5, train_acc:0.811, test_acc:0.754 ===
=== epoch:6, train_acc:0.839, test_acc:0.763 ===
=== epoch:7, train_acc:0.873, test_acc:0.769 ===
=== epoch:8, train_acc:0.878, test_acc:0.784 ===
=== epoch:9, train_acc:0.908, test_acc:0.8 ===
=== epoch:10, train_acc:0.901, test_acc:0.781 ===
=== epoch:11, train_acc:0.929, test_acc:0.796 ===
=== epoch:12, train_acc:0.956, test_acc:0.803 ===
=== epoch:13, train_acc:0.948, test_acc:0.817 ===
=== epoch:14, train_acc:0.958, test_acc:0.799 ===
=== epoch:15, train_acc:0.962, test_acc:0.808 ===
=== epoch:16, train_acc:0.956, test_acc:0.789 ===
=== epoch:17, train_acc:0.965, test_acc:0.804 ===
=== epoch:18, train_acc:0.962, test_acc:0.796 ===
=== epoch:19, train_acc:0.967, test_acc:0.812 ===
=== epoch:20, train_acc:0.962, test_acc:0.814 ===
=== epoch:21, train_acc:0.975, test_acc:0.8 ===
=== epoch:22, train_acc:0.964, test_acc:0.796 ===
=== epoch:23, train_acc:0.975, test_acc:0.804 ===
=== epoch:24, train_acc:0.974, test_acc:0.798 ===
=== epoch:25, train_acc:0.977, test_acc:0.81 ===
=============== Final Test Accuracy ===============
test acc: 0.7912
Saved Network Parameters!
time : 29704.275405168533 second
最終のtest acc(テスト正答率)は79.1%だけど、途中で最高81.4%までいったー。
しかも訓練データは97.7%の正答率になったしね。
でも時間かかったなー。約8時間か。前回のが4649秒であることを考えると6倍ぐらいになっているが、
実際にはこのうち、2時間ほどは計算を止めていた時間があるので、6時間ぐらいかな。
GPU使わないと流石につらいね。(MacのApple Siliconでは、NumpyのGPU版であるCupyは使えないらしいので、すぐに試せる方法がない)
もう一回6時間やるのはキツいので、この学習したパラメータはpickle形式で保存してある。
そして、それを使って、実際に画像を認識させてみたところ、
知り合いの犬をピクサー風に加工した写真はでもちゃんとdogと判断してくれた。
12枚中10枚正解で、
間違えた2枚は、
- 翼が写っていないジャンボジェット機をshipと判断
- 豪華客船の前半分しか写っていない写真をairplaneと判断
と、まあ間違えても仕方ないかなって感じであった。
これはテスト正答率が上がれば正解するのかな。
とりあえず、もっと色々やれば改善はできるかもしれないが、
ここまでが目標だったので、一旦これで本書は終わりかな。
ResNetとかどれくらい効果があるのか見たい気はするけど。
画像認識の各モデルのランキングサイト(下記)で、
CIFAR-10ではランキングに載っているのは最低でも75.86%だったので、これを超えることができて嬉しい。
Classification datasets results
参考
CIFAR-10でaccuracy95%–CNNで精度を上げるテクニック– #Keras - Qiita
まとめ
本書は非常に楽しかった。
自分で全部思いつくのは無理だけど、
1個1個考えながらやってみて、
やっている内容はほぼ理解できたと思う。
途中難しいなーって思うところもあるけど、
何度か読み返したり、プログラムで試してみたりすると分かることも多いので、
諦めずにやって良かった。
ひとまずこれで、画像にてDeep learningを使う必要がでてきたときに基本的な知識と感覚は身に付いたと思う。
本書にはまだまだ続編があり、
特に3巻なんかはDeep Learningフレームワークを自分で作るというので、
それも面白そうなので、そのうち取り組む気がする。
There are currently no comments on this article, be the first to add one below
Add a Comment
Note that I may remove comments for any reason, so try to be civil. If you are looking for a response to your comment, either leave your email address or check back on this page periodically.