

「ゼロから作る Deep Learning」で機械学習を学ぶ その05 CIFAR-10,100を学習させてみた
2025-07-31 14:20:44
- Tags:
- Python
- Deep Learning
今回は第7章ではなく、第6章までの機能を使って、CIFAR-10を学習させてみる。
ソースは下記
ryotakato/de_zero
CNNに入る前に、全結合のネットワークを使って、
手書き文字以外のものも学習させてみようかと思った。
最初はImageNetとかOpenImageなどが必要かとおもっていたんだけど、
どうも少なくても300GBぐらい容量が必要で、
流石に試すのにそこまで大きいのはいやなので、もっと軽いのを探すと、CIFAR-10というのが見つかった。
32x32で3チャンネルの画像が60000枚(50000枚訓練データ、10000枚テストデータ)
ダウンロードしても200MBいかないぐらいなのでお手軽に試せる。
でこれを読み込むプログラム組んで、
さらにそれを、
- 隠れ層は100,100,50の3層構造
- Xavierの重みの初期値
- Batch Normalizationあり
- Dropoutはなし
- 学習は、AdaGrad
のネットワークに通す。
最初10000回だけだと、そこまで時間がかかるわけではないので、
10倍の10万回にあげてみたら、かかった時間は478秒(8分弱)
訓練データは5万枚で、バッチサイズが100なので1 epochは500イテレーション
結果的に200 epoch
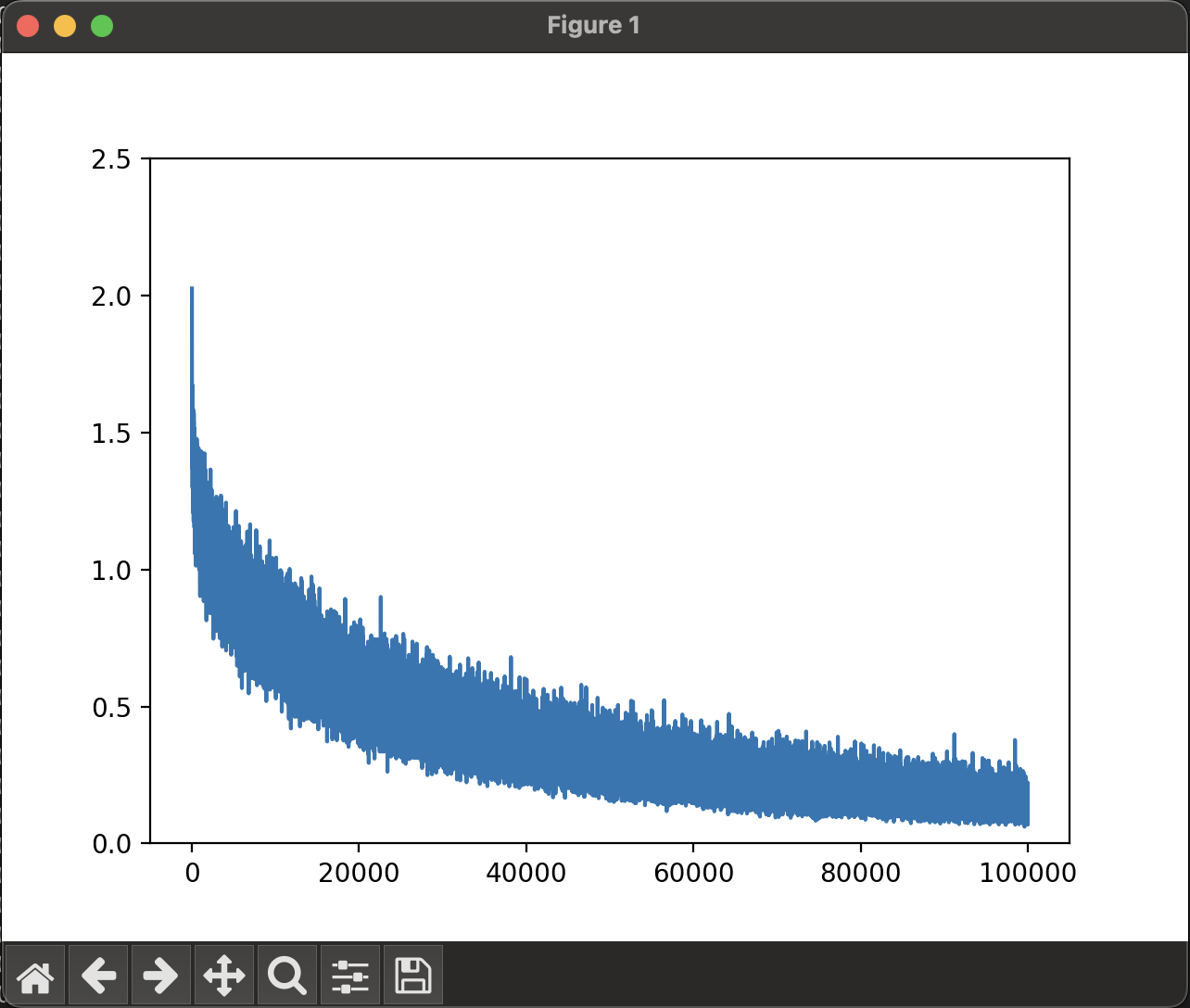
損失関数の変化はこんな感じで、いい感じに下がっているかなと思っていたのだが、
正答率の変化はこんな感じ。
訓練データに対して、テストデータの正答率が低い。
というか、学習していくに従い、少し下がっている。
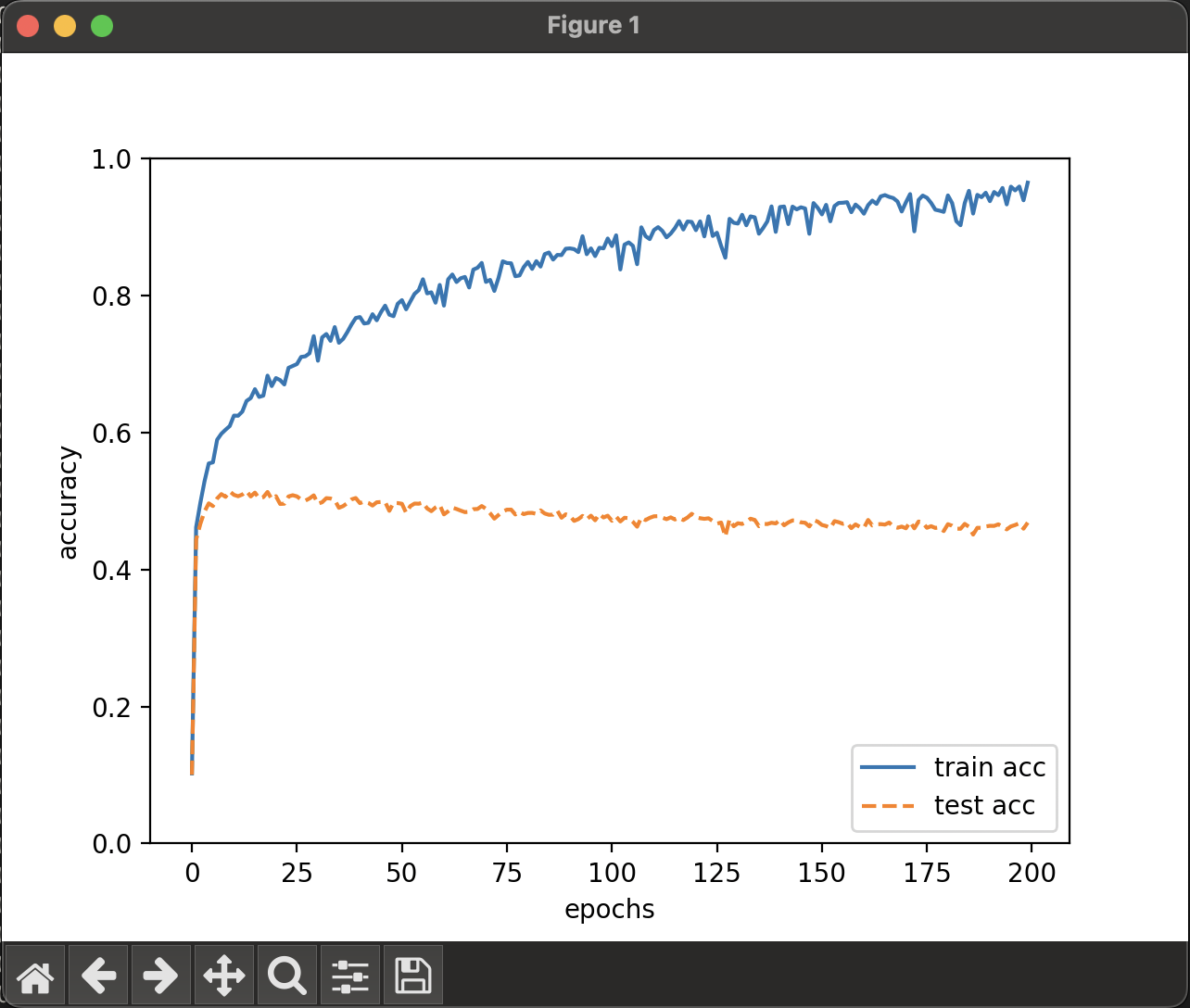
最終的な結果としては、訓練の正答率94.74% に対して、テスト時正答率は46.85 %と、かなり低くなっている。
これは訓練データに過学習しすぎたか?
epochを進んでいくと正答率落ちているのはそれが原因かも。
というか、これなら10万回もやらなくてよかったことになる。
ちなみに、CIFAR-100という、100個に分類した画像のほうで学習させてみると、
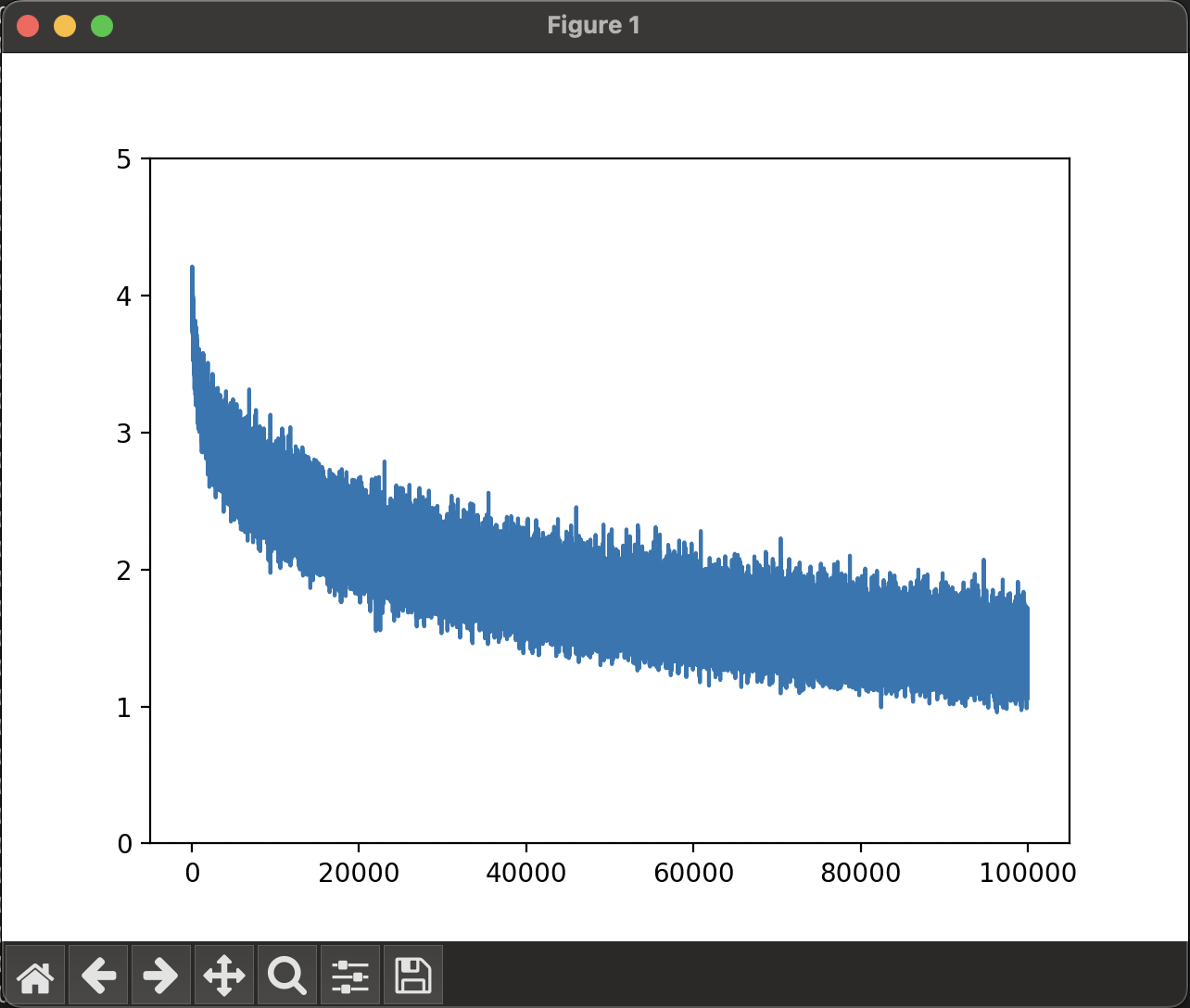
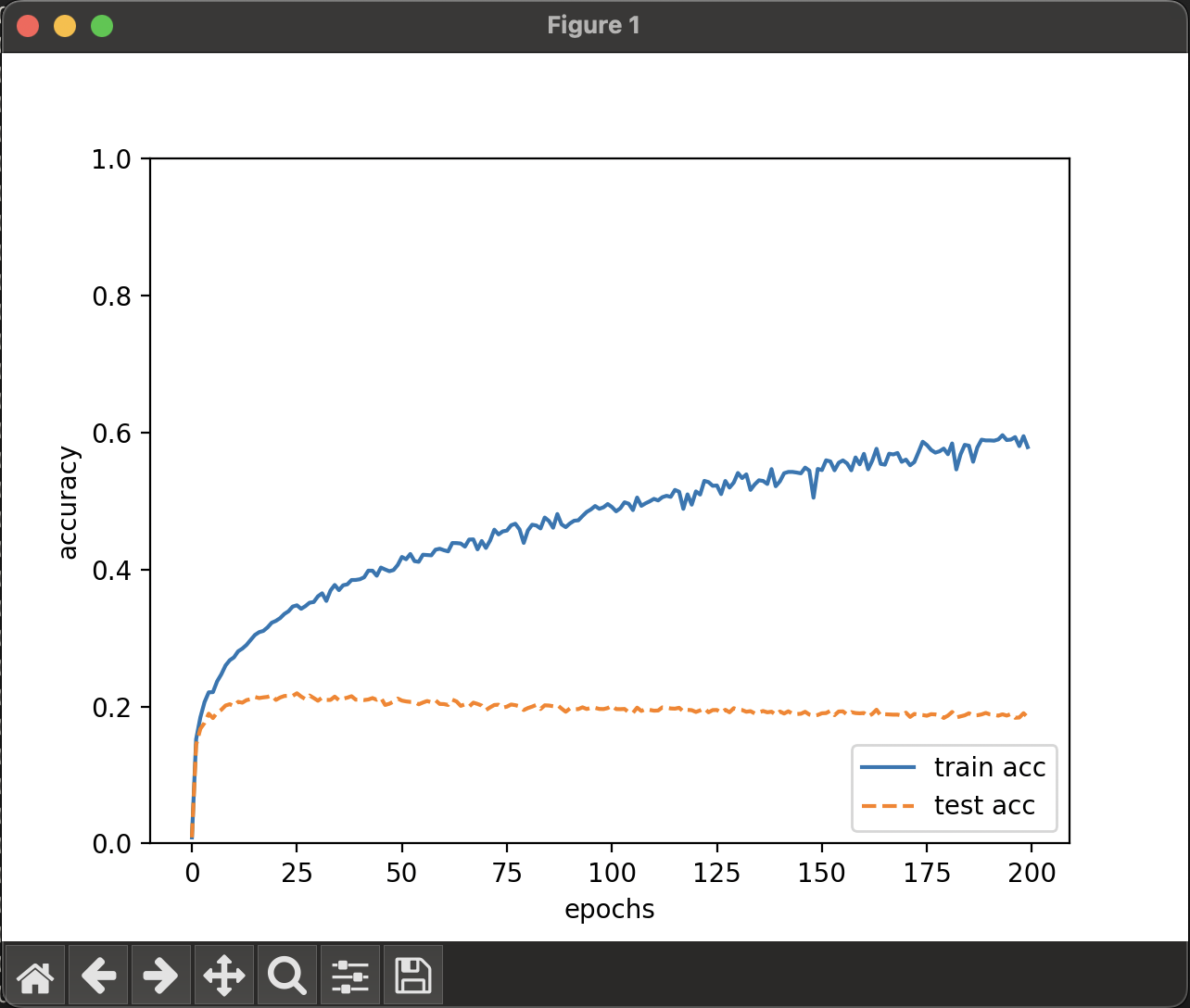
同様の結果となり、
訓練正答率 59.79 %
テスト正答率 18.47 %
という結果に。
そりゃ、100個の中から当てずっぽうで正解するよりはずっと高いけど、
20%切っているとそこまで意味がない。
とりあえずテスト正答率が上がらないほうから解決してみようかな。
過学習のせいかもしれず、
それならDropoutやハイパーパラメータの変更でいけるかもしれない。
もっと精度をあげる話は、一旦それが終わってから。
もしかしたら全結合のネットワークではこれが限界でCNNを使わないといけないのかもしれないし。
参考
CIFAR-10 and CIFAR-100 datasets
カラー画像のデータセットを探し求めて | Webシステム開発/教育ソリューションのタイムインターメディア
いまさらCIFAR-10をダウンロードして画像として保存する #Python - Qiita
[Python]CIFAR-10, CIFAR-100のデータを読み込む方法 #Python - Qiita
There are currently no comments on this article, be the first to add one below
Add a Comment
Note that I may remove comments for any reason, so try to be civil. If you are looking for a response to your comment, either leave your email address or check back on this page periodically.